- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to check the maximum of FFT size*number?
11-16-2013 09:57 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Dear all,
I want to use GPU to do multiple 1D FFT. I learnt from the example Multi-channel FFT.VI that a subVI could check the FFT size limit by using the total global memory of the GPU card. I wonder if there is any similar way to check the maximum number (batch) of FFTs given the certain known FFT size (such as 1024)?
Thanks.
Xsword
11-18-2013 10:59 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Because this could vary between different versions of CUDA, I would look first at the CUFFT reference manual on NVIDIA's website for the version you have installed.
The initialization of the FFT library before executing an FFT will pre-allocate resources on the GPU should act as the runtime check for the 'maximmum' supported for a specific GPU device.
Know apriori what will fail will probably require more than just the total memory available.
11-18-2013 08:17 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Hi, Math Guy,
I am using LV2012 64bit, GPU analysis toolkit 2012, Win7 64bit, CUDA 5.0 and below shows Get GPU Device.vi results.
I have made the following program to check the maximum # of FFTs given a certain FFT size # supported by CUDA and the GPU card:
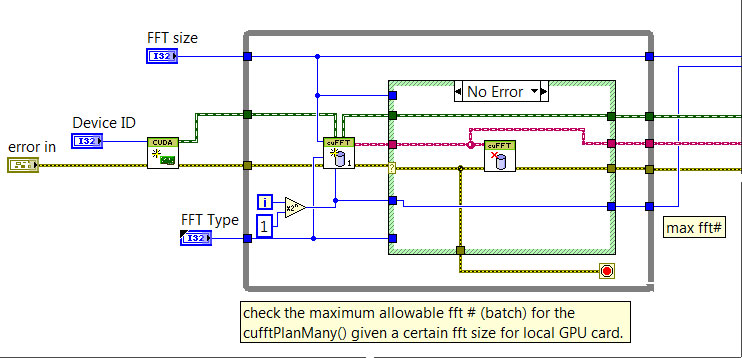
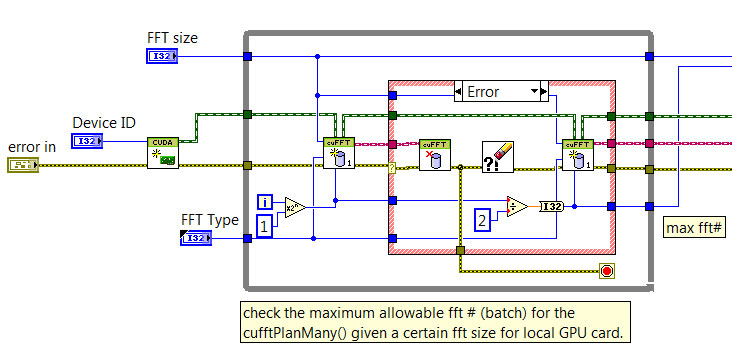
It will give me the max FFT# so that I could use as reference for subsequent memory allocation.
Xsword
11-18-2013 09:52 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
This is how I would have approached the size search but there's a few issues worth mentioning:
1. Is there a reason you are generating batches of size 2^N? The FFT implementation is optimized for FFT's of size 2^N as well as other prime factors listed in the documentation. However, the batch size can really be anything. My guess is that multiple of 16 or 32 will result in the best performance (due to the warp size on NVIDIA GPUs).
2. Initializing the library reserves resources but I don't know if it takes into account the actual GPU buffer required to hold the signal/spectrum data.
3. Even if the library initialization accounts for the FFT data, it would likely correspond to an in-place operation (signal & spectrum are the same buffer) to be most efficient. That means that initializing for a non-in-place operation would fail when you allocated the GPU buffers for the FFT data.
If this is the case, then you will have to add CUDA calls to allocate GPU buffers for your FFT inputs/output before attempting to initialize the library for a given batch size. Then, if the initialization passes, you can deallocate the buffer(s) before trying the next size.
-------------
What happens if testing for the limit this way causes the FFT to stop working?
If you looked at the Get GPU Device Information example that ships w/ the toolkit, you'll notice a Reset Device? option on the front panel. I added this because I found that on some GPUs (mostly low-end consumer cards) executing increasingly large FFTs until an error is produced resulted in a device where no future FFT calls passed even when using valid sizes.
One way to (attempt to) recover the device w/out restarting LabVIEW is to reset the device. The Reset Device function is not on a palette but you can find it by following the code path link to the Reset Device? control in the aforementioned example.
NOTE: Resetting the device from a multi-threaded environment like LabVIEW is not always straightforward. When it happens any calls after the reset will fail until Initialize Device is called. In your case, a reset condition would exist if:
(a) The initialization of size N produced no error,
(b) The initialization of size 2*N fails, and
(c) The second initialization of size N fails.
Because you are initializing the device in the same code where the size limit is tested, it is safer for you to do the reset. Once the reset is called, initialize the device (again) and then the FFT library. If that fails, LabVIEW must be restarted (which unloads the corrupted CUDA runtime engine and reloads it).
----------------------
One small coding comment:
On your last diagram snapshot which shows the 'Error' case, you can replace the Divide function by the Power of 2 primitive with -1 for the power. This performs the division by two and retains the integer type of the output.
However, if you move to testing batch sizes which are not powers of 2, you can store the previous batch size in a shift register and use it in the Error case. This would work also for your current implementation.
11-19-2013 05:14 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Hi, MathGuy,
Before I fully digest your detailed reply, I'd lile to post the full VI for checking the maximum batch # of 1D FFTs. If it is fine, I am considering to use it to initialize the subsequent FFT processing.

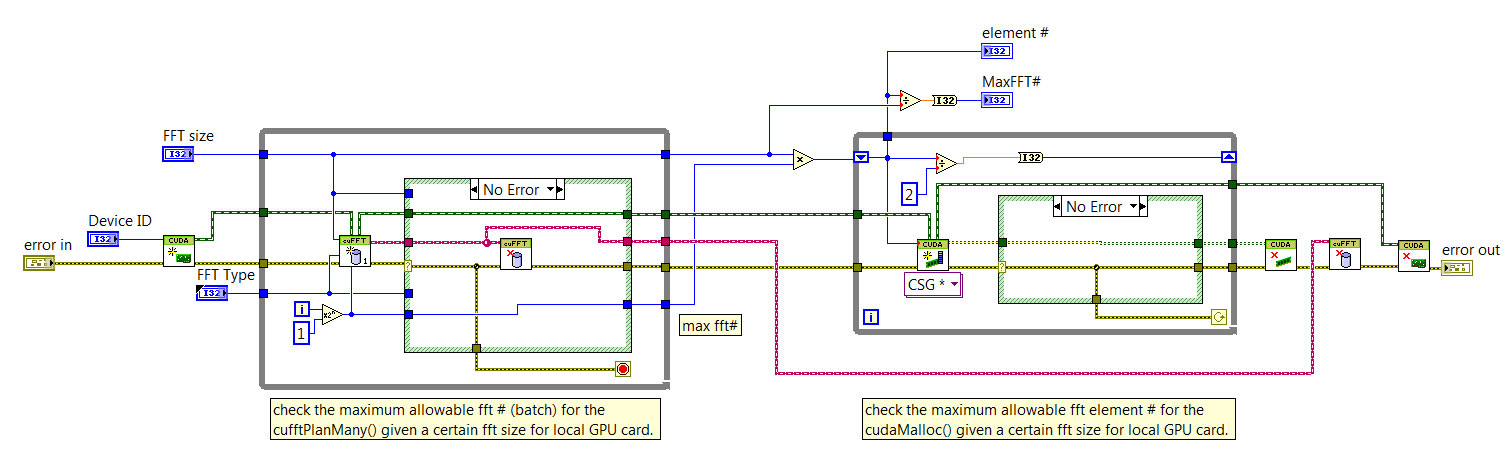
Thank you very much for your patient explanation.
Xsword
11-19-2013 07:49 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
This isn't quite what I had intended. First, the initialization of the FFT library establishes the data sizes for the FFT call. You should not attempt to execute an FFT with signal/spectrum with fewer than (FFT size x batch size) elements.
Doing so fill either generate an execution error or, worse yet, corrupt the device for future calls. Make sure you are allocating both buffers if you are not doing an in-place operation. You should try this first before making the limit search more complicated.
If this does not work, then you have to do the allocations while you are testing the maximum batch. The code would do the following steps iteratively:
- Choose a batch size.
- Allocate the buffers needed for the input/output data which corresponds to the batch size.
- Initialize the FFT library.
- If it succeeds
- free the library
- deallocate the buffers
- If it fails
- free the library
- deallocate the buffers
- allocate the buffers for the previous batch size
- initialize the library for the previous batch size
- If error
- Reset the device
- Initialize the device
- Allocate buffers for max batch size
- Initialize library for max batch size
In your latest code, you find the maximum batch size for initialization first without any GPU buffers allocated for the inputs/outputs. This will only work if the initialize library routine takes this into account. If it does this, then it is probably assuming in-place execution. If you don't plan to do the FFT in-place, you would then need to allocate the extra buffer while testing the batch size.
I'd also recommend a few coding changes based on the latest snapshots:
- Once you've found the max batch size, I would pass it outside the testing While loop and do your final (good) initialization after the While loop. Passing the valid initialized library out of the Error case is a bit strange and unexpected (i.e. a valid library reference comes out of the Error case and not the No Error case?).
- When checking for the initiailization failure, I would look specifically for the CUFFT_ALLOC_FAILED error code from the Initialize Library function. Other error codes would inidicate the limit search has generated an unexpected (fatal) error condition.
I checked the CUFFT documentation and don't see any information regarding the limit. If it is not documented anywhere, then I would recommend testing for the limit and not assume the current initialization behavior will be supported in future versions.
11-20-2013 08:57 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Hi,MathGuy,
Thank you for your detailed explanation and recomendations. I tried to read and understand your comments above. Especially, I learnt from the SubVI "Find FFT Size Limit.vi" in the "Get GPU Device Information" example quite a lot. Now my idea is to obtain the maximum FFT batch size that can be supported by my GPU card and save it into a globle variable for subsequent settings for a multi-FFT processing on my acquired data. Please see my latest code:
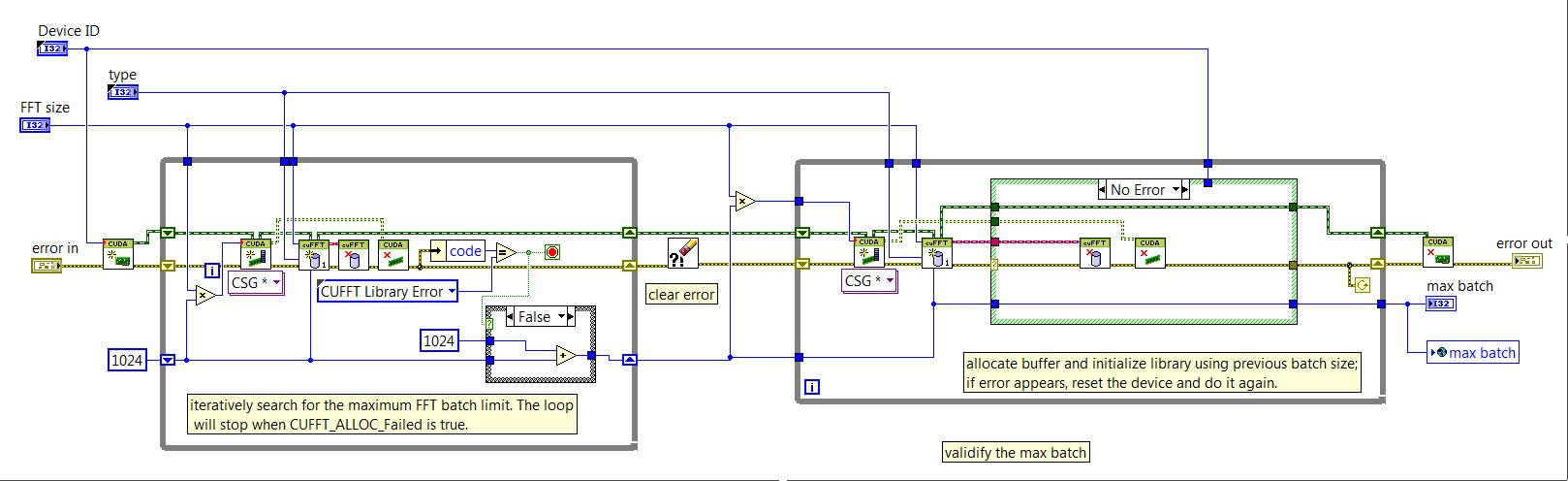
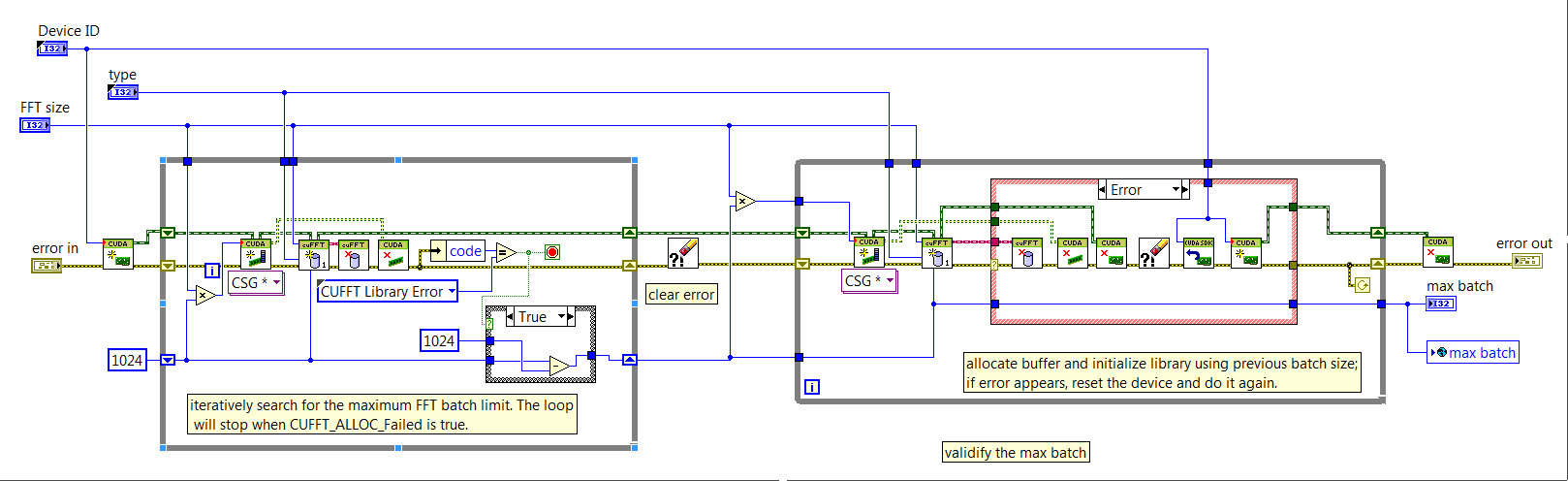
Is it now better? Thank you for your help and comment.
Xsword
11-20-2013 09:09 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Yes, that's the process model I would use. To avoid an infinite loop in the second loop, I would only attempt to reset the device once.
This can be done by (a) exiting the loop after the count is > 1 or (b) switching it to a FOR loop with 2 iterations and modifying the loop diagram to skip execution if the previous loop did not generate an error.
Storing the max batch in a global is fine but I might recommend going one step further and creating an 'FFT Batch Record' which is a cluster with the computed max batch, device name, compute capability and total memory.
Then, when you load your max batch you can verify at runtime if the GPU it will be used on matches (or is superior) to the one the batch size corresponds to. This isn't a requirement but can help debug issues if your code gets run on a different machine or you add a GPU to your system (and the device order gets changed by NVIDIA's device driver).
*** CAUTION ***
I forgot to mention this in the prior responses but I noticed that your are passing in the FFT type using a control. This means that the code you are using (based on CSG data) is only valid if the type passed in is for single precision FFTs (e.g. CUFFT_C2C) - not double precision (e.g. CUFFT_Z2Z).
You have to either inspect the incoming type and adjust your data allocations appropriately (i.e. allocate U8 buffers that are equivalent size to an equivalent CSG or CDB signal/spectrum) or block FFT types which do not define CSG based FFTs.
