- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to determine string is ASCII or Unicode?
Solved!01-21-2017 10:59 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
As title, I'm trying to detect input string is ASCII or Unicode.
I cannot figure it out. Pls kindly help if anyone.
Thanks!
Solved! Go to Solution.
01-21-2017 11:44 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
For plain Unicode vs ASCII, you can't really tell for certain (although you may be able to guess based on content).
However if it's UTF-16 vs ASCII, the first two bytes will tell you: For UTF-16, the first two bytes are a byte-order-marker (either FF FE or FE FF).
01-22-2017 01:28 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
I'm not familiar with this, could you explain how to read first 2 bytes is FF FE or FE FF in LabVIEW?
I tried to use "Read from Binary", but always get 0 0 as U8 type.
01-22-2017 09:24 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Why don't you attach both a sample data file and your code, not a picture, but the actual .VI file you are trying to use? We'd be able to make suggestions that may work for you in your context, and also help you with specific misconceptions or mistakes you've made with your code.
Bob Schor
01-22-2017 06:26 PM - edited 01-22-2017 06:32 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
As already mentioned Unicode is a coding scheme that does not only contain a single possibility. There are at least 3 major variants called UTF-8, UTF-16 and UTF-32 with the number behind the UTF indicating the number of bits a single code point does occupy. Except for UTF-32 a codepoint is not the same as a character.
UTF-8 text that only contains ASCII-7 bit characters is indistinguishable from an ASCII text file unless it contains an optional (and not recommended) BOM header (0xEF,0xBB,0xBF), although that name is really misleading since UTF-8 is a single byte coding scheme, so there is no byte order to indicate.
UTF-16 can represent most characters of all the living languages around the world in a single code point but the higher characters (usually representing special characters or from artificial languages like Klingon) are represented with multiple codepoints.
UTF-32 can currently represent all defined characters in a single codepoint of 32 bit but the Unicode standard allows for future extensions to include new characters.
To make things more interesting the two multibyte encodings UTF-16 and UTF-32 can be in big endian or little endian byte order and that is where the BOM header as the first character point (mostly used in UTF-16 encoding) comes in handy.
Most Unix systems nowadays use UTF-8 as default text encoding scheme while Windows settled on UTF-16 little endian encoding both internal to the application and when exporting and importing text data. But on Unix, Unicode aware applications use normally internally the wide char representation which on Unix maps to 32 bit Unicode encoding. But when exporting it to and importing it from streams like files, network connections, etc it is usually converted to UTF-8.

01-25-2017 08:43 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Thanks for above reply.
Let me explain my question clearly.
I used Unicode support in my LabVIEW development as following metioned:
http://forums.ni.com/t5/Reference-Design-Portal/LabVIEW-Unicode-Programming-Tools/ta-p/3493021
In my application, I hope to programmatically determine the decode type of input String, which could be ASCII or Unicode.
Following is an simple example for attached VI:

String "ASCII" is original LabVIEW text, and "Unicode" is Unicode string produced by method "Force Unicode Text" mentioned in above link.
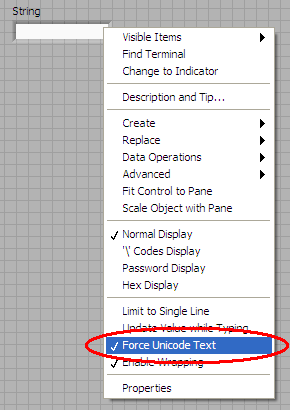
I'm not sure if this is possible or not, but I cannot figure out a nice solution.
Pls kindly let me know hot to achieve this.
Thanks!
01-25-2017 12:21 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Make sure that whatever supplies the string uses UTF-16 LE when it's Unicode, then just check the first two bytes of the string.
01-31-2017 09:25 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
The input string is not supplied from Unicode file.
It's just fixed constant string in LabVIEW.
Most of time, there won't be first two bytes for Unicode string.
01-31-2017 10:07 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
If the first two bytes are not present, then it isn't "truly" Unicode. It's just an array of bytes waiting to be interpreted somehow. I think you will have to interpret the bytes depending on where they came from.
(Mid-Level minion.)
My support system ensures that I don't look totally incompetent.
Proud to say that I've progressed beyond knowing just enough to be dangerous. I now know enough to know that I have no clue about anything at all.
Humble author of the CLAD Nugget.
01-31-2017 10:15 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
In that case, there is no sure-fire way to tell the difference. An ASCII string might contain any sequence of bytes, and a Unicode string also might contain any sequence of bytes, If you display a string as ASCII, then as Unicode, you may find that one is readable (in some language) and the other looks like garbage; thus you could infer the coding. However doing that programmatically is probably intractable. Your best chance (and it's not a good one) is to assume that any Unicode string will contain some (maybe many) characters in the codepoint range 1-255. If there are nulls in the even bytes, it's probably UTF-16 LE. If there are nulls in the odd bytes, it's probably UTF-16 BE. If there are no nulls, it's probably ASCII.
