- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- « Previous
- Next »
Welcome to LabVIEW High Performance Analysis Library
08-11-2011 11:03 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Hi Greg, thanks for the interesting benchmark. These results are expected. Let me briefly explain the reasons.
1. HPAL function is slightly lower than buildin vi.
Actually, both HPAL and the buildin vi call into Intel MKL routine. So ignoring the threading issue, they are supposed to have the same performance. Unfortunately, when you put the HPAL vi in a Par-For-Loop, the threading issue will introduce overhead. Compared to the small size of your vectors, the overhead would be considerable.
2. HPAL function is considerably slower than primitives.
Similarly, HPAL or buildin vi has overhead. They come from calling a subvi, using a 'call library node' ... On the other hand, in LV 2010 and 2011, our developers did a lot of optimization on the primitive functions. So at small size, you will find the primitives are significantly faster than HPAL/buildin vi.
To get better performance in your application, especially when the problem size is small, one suggestion is to reduce the overhead from function call. For example, if you already have all 2000 vectors ready in a matrix, I would recommand you to use gemm in BLAS palette. It is almost 10x faster than primitives on my computer.
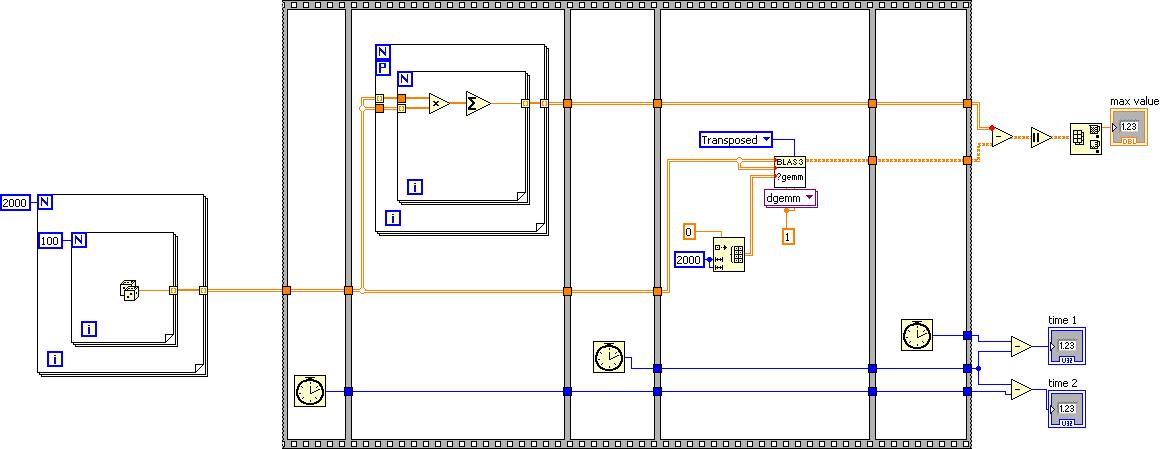
11-10-2011 09:07 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
I'm also very interested in a 64-bit version. Will it be ready soon?
11-10-2011 10:32 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
The news about 64-bit version will be posted in a few weeks. 
- « Previous
- Next »
