- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Community Nugget 4/08/2007 Action Engines
Solved!04-08-2007 08:37 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
In a nut shell tst has nailed it except for the “Ben’s term” part. I was originally exposed to the term "Action Engine"
Functional Globals (FG) are VIs that are functionally equivalent to LabVIEW globals. Functional Globals store

USR.jpg
Shift Registers (SR) come in two varieties “Initialized” and “un-initialized”. The presence or absence of a wire

In the “Write” action (not shown) the value of “Numeric in” is placed in the USR. In the “Read” action the contents of
An Action Engine (AE) can be thought of as a machine (Engine) that performs some useful task (action) often on
AE design revolves around the ways the shared resource must be accessed manipulated or monitored. In a Functional

Running_Average_Example.jpg

Parallel_Loops.jpg

Init.jpg

Add Num.JPG

Solved! Go to Solution.
- Tags:
- Action
- ActionEngine
- AE
- Ben_ActionEngine
- community_nugget
- condition
- Encapsulation
- engine
- example
- fgv
- functional
- FunctionalGlobal
- global
- Globals
- LabVIEW
- LabVIEW_ActionEngine
- LabVIEW_ActionEngine_Solenoid_Valves
- LabVIEW_ActionEngine_Solenoid_Valves_Control
- LabVIEW_ActionEngine_SolenoidValves
- LabVIEW_Global
- LabVIEW_Locking
- LabVIEW_LockResource
- local_variables
- Lock-Resource
- locking
- LockResource
- new
- Non-Reentrant
- Nugget
- Nugget-ActionEngine
- race
- Race-Condition
- Required_Reading
- resolution
- Resource_Sharing
- Solenoid_Control
- Solenoid_Valves
- Solenoid_Valves_Control
- valves
- variable global funcional
- variables
- VI-Server
04-08-2007 08:58 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Nugget continued
The Traffic Cop Behind the Scenes
A detail I have not mentioned up until now is that AEs should be implemented as VIs that are not reentrant***. VIs that are not reentrant can only be executing in one context at a time. LabVIEW will ensure that if there is ever a situation were two contexts are attempting to act on the same AE at the same time, LabVIEW will schedule the first and the subsequent will wait until the first call completes. This is similar to a traffic cop preventing more than one vehicle from entering an intersection at the same time. The Traffic Cop is illustrated in the following timing diagram were we look at how the processing of two threads is affected by using a single AE.

Execution_Timeline.JPG
In the figure above the processing time of two processes “P1” and “P2” are illustrated by a red or blue solid arrow respectively. In the parallel loops example shown earlier, P1 could be the “Calc Mean” loop and P2 could be the “Add Number(s)” loop.
t0 - t1
Both processes are executable and run their assigned tasks. Neither process is accessing the AE.
t1 – t2
P2 continues to run while P1 calls the AE. Since the AE is idle it is available to run so P1 continues execution running inside the AE until all work inside the AE completes. The dotted arrow shows that the thread for P1 is executing in the data space allocated for the AE.
t2 –t3
At t2 the AE terminates and both process run as in t0 – t1.
t3 – t4
This time segment is similar to t1 – t2 with P2 running in the AE.

t4 – t5
Similar to t2 – t3 the AE terminates and both process run.
t5 – t6
Similar to t1 – t2. P1 take control of the AE.
t6 - t7
At t6 P2 attempts to call the AE. Since the AE is not idle it is not available to run. P2 is placed in a resource wait state (it is NOT running) waiting for the resource to become available. The dotted horizontal arrow indicates the process is not executing.
t7 –t8
At t7 the call of the AE by P1 that started at t5 completes and P1 continues to execute outside of the AE. When the call by P1 completes the AE becomes available. The process P2 is marked as executable. The scheduler includes P2 in its executable threads and the AE is available. P2 then executes inside the AE until the call completes.
The Beauty of the AE
This behavior of a non-reentrant VI is a wonderful feature we can exploit to eliminate race conditions. Race conditions are the nemesis of many a developer. In hardware this was solved with clocked enabled logic. In LV we solve race conditions with Queues, Semaphores, Rendezvous, Occurrences, and Action Engines!AEs can eliminate race conditions when all operations involving updates of the data stored in the USR are done INSIDE the AE. A very simple illustration of how the encapsulation of USR manipulation is shown in the following set of examples.

Port_With_Global.jpg
This VI is intended to demonstrate how two bits of an eight-bit port can be used to control the running state of two pumps. To illustrate the control process, one pump will be set running at start-up and then every half second the state of both pumps will be toggled to simulate switching of the supply. This example uses globals and fails miserably.

Port_With_Global.jpg
In this example we start out by initializing a global variable so that bit “1” (zero based) is the only bit set in an array of eight bits. This turns on Pump 2 to start. Then the “Port Update” and a “State Change” loops run in parallel. In the “Port Update” loop the state of the port is read from the global and used to update the GUI.
In the “State Change” loop, the port status is read and the first Boolean is inverted before being written back to the global. Similarly for the second Boolean. Since the read of the globals both occur before the subsequent data processing, one of the threads will be processing old data.
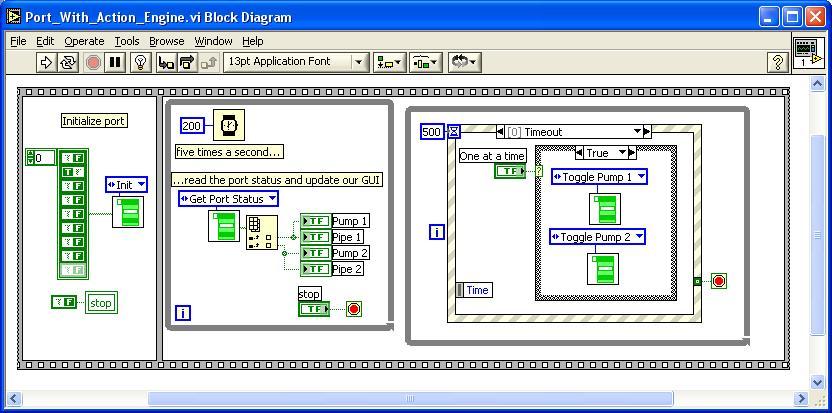
Port_With_Action_Engine.jpg
The Action Engine version codes up the same way as the global version but now all of the data manipulation of the port states are encapsulated in the Action Engine “Port Controller”. This encapsulation ensures all operations involving the data in the USR are forced to happen sequentially even though we did not have to implement any code to achieve this affect.
The key point to take away from this example is a shared resource (the port status in the case) when implemented as AEs come with resource contention resolution built in provided that all manipulation of the shared resource takes place inside the AE.
Action Engines to the rescue!
Action Engines are not a replacement for Queues, Rendezvous and the other synchronization techniques. They are typically called for when your design dictates that a single resource must be shared by more than one parallel process and none of the LabVIEW provided techniques are sufficient. They require a design of their own to ensure they work correctly. They also have to be developed and supported.
This Nugget is continued in the next post
04-08-2007 08:58 AM - edited 04-08-2007 08:58 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Wrapping It Up
After submitting this Nugget for review by my fellow Champions, Jim Kring mentioned that he wraps up his AE calls in sub-VIs. This is a wonderful way of solving two challenges associated with AE use. The first challenge is not being able to set important inputs to the AE as “Required”.
If we develop a wrapper VI for each type of AE call, we can designate all of the required inputs for proper operation of the AE function call as “Required”. Without using the wrapper VI to ensure the proper calling convention, the inputs required for ANY AE function would be required ALL AE calls.
Example. Suppose you have an AE that stores all of the user information in your application. Among other functions the AE includes the actions “Set User Password’ and “List all Users”. Since a “User Name” input is required for setting a users password correctly, this input would be required when attempting to get a list of all of the user with the “List all Users” action. By wrapping up the individual actions in appropriate wrapper Vis, we can set the “User Name” input as required in the “Set User Password” wrapper. The “List all Users” wrapper would not have a “User Name” input.
A second benefit of using a wrapper VI for each action of the AE is in making maintenance easier. Since each type of access to the AE is encapsulated its own VI, a search for a selected wrapper VI is a search for all actions of that type. If you know there is only one type of action that can cause a condition you are trying to modify, you can quickly find all of the code that can be affected by changes to that action.
Closing Notes
1) When using your AE remember the data is in the USR.
2) Let your data define your actions
3) Avoid super clusters
4) Hierarchies of AEs help keep your data structures simpler
5) Self initializing and recursive AE are both elegant and efficient
6) AEs do not require a While Loop.
Questions
7) Do you have a process that you go through when designing AEs, what is it?
😎 Does anyone use the techniques used for Normalizing Databases to AE design?
9) Do you think that a USR is required for a VI to be considered an AE, e.g. "Could use a dll call and still call it a AE?"
If you have a Nugget you would like to present please post here to reserve your week!
A list of all Nuggets can be found here.
I want to offer thanks to Albert Gevens and Jim Kring for their assistance in creating this Nugget.
Foot Notes
*LabVIEW Programming Techniques" produced by Viewpoint Systems Version 2.2 August, 2000 page 67. I believe this book was the precursor to the original version of NI’s "Advanced Applications Development Course"
**An Action Engine is generally implemented as a VI that is not reentrant to share the USR across multiple instances of the sub-VI. A reentrant VI will allocate a unique data space for each instance of the VI.
***Come on Ben can’t you go a couple of Nuggets with out bringing up reentrancy? Nope.
**** A “Race condition” is a term used to describe the situation were information from different sources are not consistent with each other. This term originated in the hardware of computers were address and control signals could arrive at the inputs of chips at different times resulting in the new control state applying to the old address (for example). In LabVIEW this condition exists whenever there are two writers of an object (Global, Local, etc) that are executing at the same time.
***** Please see the previous Nugget “Type Definitions Let You See Your Application in a Different Way” found here .
Type def’d enums are highly recommended for AE development because the case structures cases will adapt to the enum changes when the type def’s are changed. When you use enums it is prudent to give some thought to how you want you AE to respond to new actions being added. If your AE has a action which is not destructive, e.g. “Read” you can assign it as the default action allowing new action s to be added without changes to the AE. If every action requires a developer’s attention, then do NOT define a default action. The AE will break until all of the actions are accounted for by the case structure.
Message Edited by Ben on 04-08-2007 09:01 AM
04-08-2007 10:06 AM - edited 04-08-2007 10:06 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
This is the longest nugget I've ever read. I take my time to read trough it but I'm already sure it's good.
Thank you Ben!
EDIT: I think you raise an important question about access to shared resources and how action engines help to deal with access to shared resources. This issue becomes especially important when using shared resources in LabVIEW object oriented programming. If one wants to implement a class level variable similar to C++ or Java static variables, one needs to control the access to this variable somehow to avoid race conditions. Locking a class level variable is not an option as every single object of that specifc class gets locked up. Action engines come in help here as they allow encapsulating action together with a shared resource. So instead of using shared class level variables in LabVIEW object oriented programming, I recommed using class level action engines.
I won't go in to detail on this issue now. I'll be writing an article series Introduction to LabVIEW object-oriented programming at my blog EXPRESSIONFLOW (expressionflow.com). This action engine shared class-level resources is an issue I will raise up in this series later on when I've covered enough basics so that this issue is clear for the readers. Subscribe to the RSS feed not to miss it.
Tomi
Message Edited by Tomi M on 04-08-2007 06:26 PM
Tomi Maila
04-08-2007 10:46 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Great Nugget. I love the term "action engine".
Some minor comments.
(1) One performance related item is worth pointing out because new users might be tempted to do things wrong:
It has been discussed very long ago that it apparently makes a significant performance difference, depending if the terminals of a subVI are placed inside or outside the structures. "Outside" is better and the given examples are correct in this respect!
For example, some might be tempted to place the "Numeric in" and "Array in" terminals inside the "add Numbers" case because they are not really used in the other cases. Similarly, the "Numeric out" could be placed inside the "mean" case, because it is the only case that produces meaningful (sic) results for it. These design changes will probably produce an undesirable performance hit.
(2) Some LabVIEW zealots (not necessarily a bad thing) might also point out that the "array out" is useless because it simply duplicates whatever input arrives at "array in". In this case it makes no sense to even have that output. Also the "Numeric out" should be renamed to "mean out" and should produce e.g. NaN in all actions except "calculate mean".
(3) I don't see a problem with the mean of a single number, it gives a well defined result. We only have a problem if the array size is zero, in which case we should produce a NaN. This happens automatically so no extra code is needed.
(4) let's also not forget the "first call?" function. Sometimes it can be used to design a self initializing action engine.
04-08-2007 11:31 AM - edited 04-08-2007 11:31 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
You can download "the last functional global you'll ever have to write" from
http://jabberwocky.outriangle.org/LV2OO_Style_Global_v1.0.zip
Detailed information about the .zip file can be found on page 10 of the PDF file:
http://forums.ni.com/ni/board/message?board.id=170&message.id=216094&requireLogin=False
Message Edited by Aristos Queue on 04-08-2007 11:33 AM
04-08-2007 01:07 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
There is one case where having the array out is a good idea. It's when your array is huge and you want to be sure that no extra buffer copies of the array are made. If you duplicate the wire on the caller block-diagram then there is a risk of an extra and unnecessary buffer copy.(2) Some LabVIEW zealots (not necessarily a bad thing) might also point out that the "array out" is useless because it simply duplicates whatever input arrives at "array in". In this case it makes no sense to even have that output. Also the "Numeric out" should be renamed to "mean out" and should produce e.g. NaN in all actions except "calculate mean".
Tomi Maila
04-08-2007 07:01 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Are you sure about that? My gut feeling tells me that creating an unneeded output terminal cannot prevent an extra copy. Maybe somebody can make a test VI and see. 😉
Tomi M wrote:There is one case where having the array out is a good idea. It's when your array is huge and you want to be sure that no extra buffer copies of the array are made. If you duplicate the wire on the caller block-diagram then there is a risk of an extra and unnecessary buffer copy.
04-08-2007 08:16 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
National Instruments
04-09-2007 05:44 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Thank you so munch for this Nugget this is the best one I have seen so far in this community.Thanks once again.
CLAD
Certified TestStand Architect
