- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
I need help w/ speed up parsing of spreadsheet string
09-14-2007 12:24 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Cheers!
09-14-2007 01:03 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
09-14-2007 01:16 PM - edited 09-14-2007 01:16 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
I don't see any \s (space) in the text following the Search and Replace in my example. See attched image.
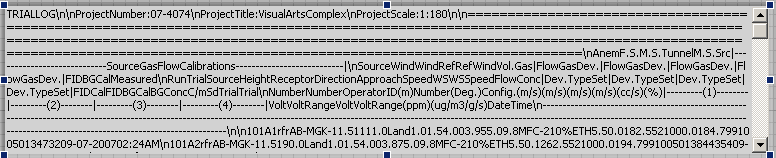
Did you use the one I loaded in my previous post?
It's supposed to remove white spaces.. or.. did you change that one to have tabs?? You may have to post your new code...
If you changed it from empty string to tabs.. okay.. humm..
Message Edited by JoeLabView on 09-14-2007 02:20 PM
{kind=link}
09-14-2007 01:31 PM - edited 09-14-2007 01:31 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
@jmcbee wrote:
When I say "duplicate" i mean that I want each group of consecutive \t's to be replaced with just one \t.
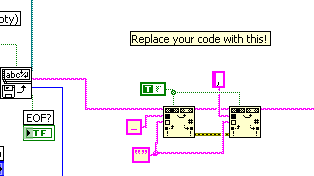
Easiest would be to use "scan strings for tokens". It automatically contracts consecutive delimiters into one. Here's a quick example. Maybe you can adapt it to your exact requirements. In this case it also stepts through the entire string only once, while all these consecutive "replace all" operations need to start from the beginning.
In this case it gets each line and then separates all elements with tabs. In this example case, it elmininates any extra \s, \t, comma, hyphen, |.
Modify as needed. I don't really know what you need exactly.

Message Edited by altenbach on 09-14-2007 11:31 AM
{kind=link}
09-14-2007 01:43 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
09-14-2007 01:56 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
@altenbach wrote:
Sorry, there is a small bug! Please remove the two "=0" wired to [i] (inner and outer loop)!
Since delimiters are diagram constants, we probably don't need those anyway. In any case, even if we wire the "cached?" input, it should be a "!=0" (not equal zero). Check the online help.
09-14-2007 01:56 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
I agree with Altenbach.
I created an example code, but unless we know what you want to accomplish in the end, I might be sending you in the wrong direction..
Thanks Christian 🙂
09-14-2007 02:08 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Cheers!
09-14-2007 02:13 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
To answer your post, I wanted to parse out hyphens and not spaces in the original example, I may have included the wrong subvi sorry if that is the case. When I remove all spaces there is no longer a delimiter between columns so I cant parse the data. I hope that clarifies.
Cheers!
09-14-2007 02:19 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
So, your code is going to have "16\tL" and "AB\t-\tMGK-1" whcih you will interpret incorrectly when you go to convert it to an array.
If you are trying to write an interpreter for this specific type of file, then you should look into using scan from string in the string pallete. Depending on what you want for output from your VI, you can build all the 1D arrays in the correct data type (i.e. DBL or string). If you KNOW that your data won't have a string in it, you can use "Scan string of characters in set" with a space for the character string, and then use a "Scan string for characters not in set" and again use a space for the character string. Throw away the first string from the scan and the second will have your data.
If your data will have spaces, then use the "Scan string (abc)" and specify the column width. Then use Trim whitespace to remove the beginning and trailing spaces. Then you can have your data with spaces in it.
If you scan all of your data as strings, you can turn it into a 2D array of strings to pass out and your code will be a drop in replacement for the Read in Spreadsheet File VI, but only supporting a 2D-array of strings. The user can then convert the strings to whatever data type it should be.
This method won't work for a file with a different layout since the column widths will vary.
