- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
In Place Element Structure speed
11-30-2007 11:08 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
11-30-2007 11:37 AM - edited 11-30-2007 11:43 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Your test is meaningless because:
- Concatenating a string cannot be done "in place" because the memory footprint is changing.
- The way you wire things into the inplace structure is also incorrect. You would need to wire your data that should be "in place" via a "inplace In/Inplace out" terminal pair. Right-click to create.
- In the vast majority of times stuff that can execute in place WILL be executed "in place", even without that structure, so there will be no difference.
- The inplace structure is a very advanced tool to be used in the very rare case when the compiler needs a hint. This is very rare and also requires you to have deep knowledge of LabVIEW. A good tool to look for problem areas is to "show buffer allocations". If there are no black dots, the inplace is not needed.
- You have two parallel loops without a wait, meaning each loop will spin many times before releasing the CPU to the other loop. This will also depend on the number of CPUs. If you would place a 0ms wait in each loop, they will more fairly alternate on a single CPU system.
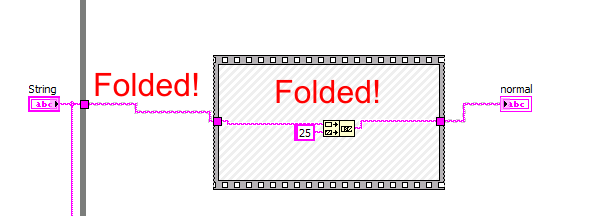
- Since your sequence frame deals entirely with constant values, it is folded into a constant and no longer processed at runtime. That's why it is faster. It does no do anything! Place the control terminals inside the loop and convert the diagram constants to controls for a fair comparison. You should enable the display of cconstant folding to be more aware of these things (see picture below). Actually, both loops are folded, so you are basically measuring the speeed fo reading the stop boolean terminal and updating the loop counts. Not very interesting!
- To benchmark, you should use a three-frame sequence with the testing code in the middle frame (Possibly in a loop). Take the tick count in the first and last frame and then subtract them to obtain the code duration. Make sure that all controls and indicators are ouside the sequence, and that nothing can execute in parallel to the sequence. Disable debugging and make sure youre not running any other heavy processes at the same time.
Message Edited by altenbach on 11-30-2007 09:43 AM
{kind=link}
11-30-2007 01:19 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Hi altenbach,
thanks for the reply. You're correct, I've made a few errors. It seems that resolving the folding has done it. I've placed two controls, one inside each while loop and had them run through the structures, containing the same data. It seems that the In-Place structure is 2% faster in this case. You can take a look at my vi here. The wiring was just a mistake I didn't save in the file.
Thanks,
11-30-2007 01:34 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
11-30-2007 01:48 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
altenbach wrote:
A 2% difference is meaningless. (the difference is a bit larger if you disable debugging, but still irrelevant).
11-30-2007 02:00 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
